The New Real Observatory platform is a machine learning tool built with and for artists.
It allows for multi sensory exploration of possible futures as co-constructed experiences of human-generated datasets and artificial intelligence-driven interpolation.
Scroll down to read more about the new Word2Vec feature on the platform, part of the New Real 2023 AI Art Commission.
INTRODUCTION
Here we describe how you can use our AI platform and your textual data to develop an art project.
For the 2023 commission we have added an ability to work with natural language processing, words and texts. This is new for 2023, the first release of our platform in 2022 worked with images and Generative Adversarial Networks, you can read about that here: https://www.newreal.cc/platform
We aim to give artists a level of control and access that you don't get in the current generation of AI tools. We develop tools to enable you to probe and explore that latent space so that the model can be better understood when you are creating a work. We want to explore how you can use the platform to make work and see if it can open up possibilities that you don't get if you don't have that level of control.
This new extension of our platform in 2023 enables you to train and explore a model on words or a collection of books and magazines, to find fresh perspectives that you can build on in the development of an artistic work, or look for associations and "conceptual slippages" in the words generated. As an artist, you can use it to expose biases within a collection of books or magazines, or get a sense of and explore the way in which machine intelligence makes sense of the world.
DATA
Using our platform you can train your own model using textual data you identify (books, magazines, newspapers, poetry, etc.), or work with a model pre-trained on Google News. We make available inspirational data from the British Library and Living With Machines project. You will want to go on a journey of discovery to find data of interest to you.
WORD2VEC
We use a Word2vec algorithm to learn word associations from a large corpus of text, which constructs a latent representation where each word is represented by a multi-dimensional vector. From a corpus of text, the algorithm will find the shortest path between any two words. Hence, the relative position in the latent space reflects the patterns of co-occurrence of words in the dataset, which can be used to generate new insights and draw analogies. In short, the model represents the AI's view of the word associations in the corpus of text it models.
Word2vec has been around for a while and is not as advanced as the 'large language models' (LLMs) used in generative tools such as ChatGPT. Large language models capture more information and consider context, and in many ways are more advanced. We are using an older technique, but doing something interesting with it.


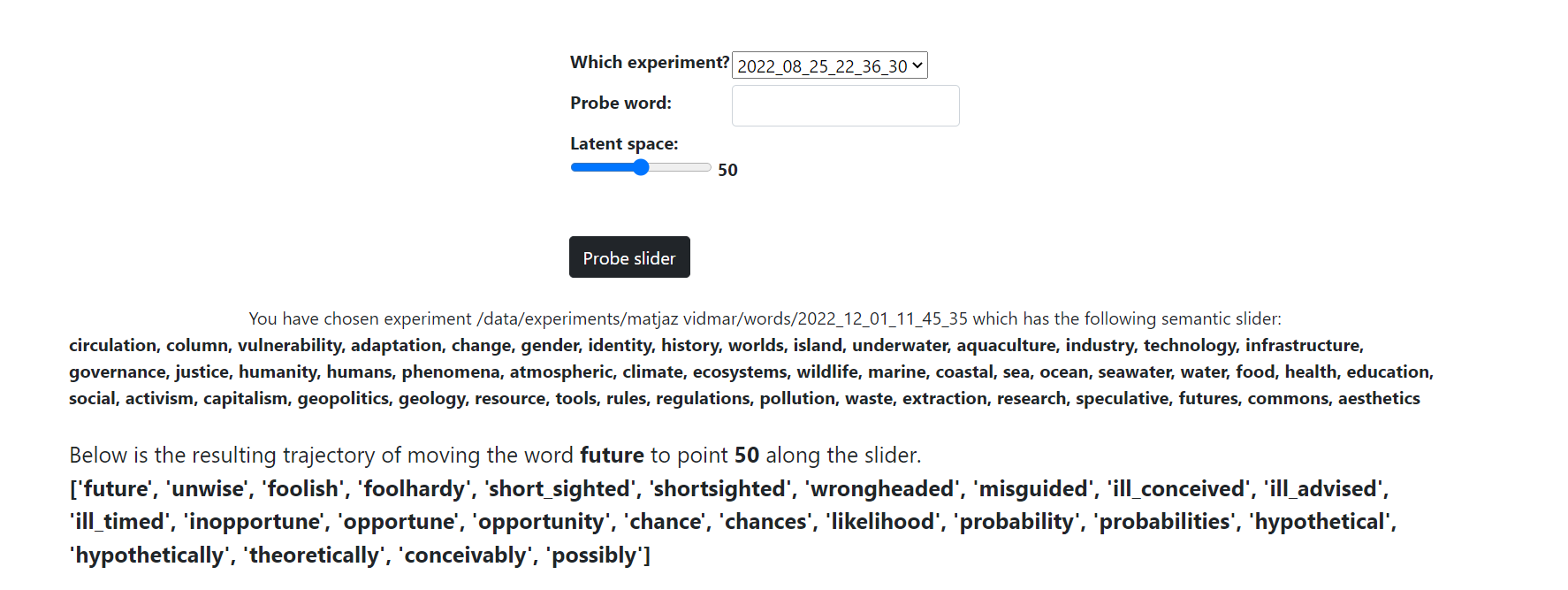
EXAMPLE 01 FROM TBA21 WORKSHOP
Just to give you a very quick illustration, we were lucky enough to be able to test it in a workshop we delivered with some fantastic artists and our friends at TBA21. In the workshop, we used tags that are used to define TBA21’s Deep Ocean Archive, to define a conceptual dimension. Using the pre-trained Google News latent space, we probed this dimension with the word ‘future’. We found that the results it generated were really dystopian.
This helps us to see the interesting and sometimes surprising results you can get. This provides a lens or perspective on training data that is novel, it speaks a truth about the data we might not otherwise observe, but it does it through this particularly statistical lens.
Going beyond the experiments in the workshop, we might build on that insight by developing a narrative work around the future that current news data reveals to us, or a work that might inspire action to change that future, or a work that probes further about the statistical worldview of which this future is a part.
EXAMPLE 02 FROM TBA21 WORKSHOP
In a second experiment, one of the artists, Ola, used a string of words from her own personal definition of the Ocean Archive to construct a dimension and use as probing word the word life. Words such as folklore and mythology were generated as she moved along the dimension with the slider.
We then bring our human understanding to interpret this, and conclude that in the current scientific and industrial literature about the deep sea life doesn't feature except as an edge case. Life is a secondary concern to commercial exploitation. Those precious, fragile creatures and habitats only register as a kind of frivilous fringe through words like folklore and mythology.
Again, this can be a jumping off point, in a work that might be built from those words, or that might simply be prompted by this conceptual exploration.
SUMMARY
We invite you to curate the training data to create a latent space of word associations relevant to your conceptual response to our Art Commission theme: Uncanny machines. We then envisage you will want to define and explore multiple dimensions within that latent space in order to probe the AI’s ‘understanding’ of the textual corpus you selected in relation to your conceptual interests. Based on the results of these explorations, you can develop a proposal on how this can be used to create significant art.
DIMENSIONS & SLIDER
With a our SLIDER tool, we are introducing an ability to define/construct and interrogate 'conceptual dimensions'. These are queried as a string of words of your selection, either from a small textual corpus or a series or keywords describing evolution of a thought or some natural or artificial quality (think of a sequence such as: desert, arid, dry, humid, wet, flooded, water, sea). The platform will locate these words within the latent space (as long as they are present in your corpus) and then map the shortest path between them all - thus outlining your ‘conceptual dimension’.
You can explore its ordering (the fact that the words in the latent space may be ordered in a different way that that envisaged by you!) as well as by adding another probing word and examining its relationship (distance) to that dimension. The dashboard will display a visualisation that flattens the latent space to 2D, with the slider represented as a straight line.
Image description: Conceptual dimension made of four words (man, beast, animal, machine) within Google News pre-trained model
In addition, the platform will generate a 'slider' user interface for that dimension that you can use to investigate the word associations generated in the latent space of the model. Using your slider you can navigate through the latent space to explore the associations the model throws up. You can also use 'probe words' to explore and generate new associations, i.e. move along the dimension if you were to look for neighbouring words in the same direction. For the humidity dimension outlined above, you might enter the word ‘climate’, and then use the slider to see what words and associations the model throws up.
Image Description: Slider text output for the experiment described in Example 01 (below)